Effizienz steigern mit dem incident management prozess

Ein Incident Management Prozess ist im Grunde Ihr organisierter Notfallplan für die IT. Es ist der strukturierte Ansatz, um unvorhergesehene Störungen in IT-Diensten so schnell wie möglich aus der Welt zu schaffen und den Normalbetrieb wiederherzustellen. Das oberste Ziel? Die negativen Auswirkungen auf Ihr Geschäft zu minimieren und eine hohe Servicequalität zu sichern.
Was ist ein Incident Management Prozess wirklich?

Stellen Sie sich den Online-Shop Ihres Unternehmens während einer riesigen Rabattaktion vor. Plötzlich geht die Website offline. Jede einzelne Minute, in der Kunden nicht bestellen können, bedeutet verlorenen Umsatz und schwindendes Vertrauen. Genau hier springt der Incident Management Prozess ein – nicht als trockene Theorie, sondern als Ihr strategischer Rettungsanker.
Ein „Incident“, also ein Vorfall oder eine Störung, ist jede ungeplante Unterbrechung oder auch nur eine Verschlechterung der Qualität eines IT-Services. Das kann ein kompletter Serverausfall sein, eine quälend langsame Anwendung oder ein Drucker, der einfach den Dienst verweigert. Der Prozess fokussiert sich einzig und allein darauf, diese Störungen schnellstmöglich zu beheben und den Service wieder in den grünen Bereich zu bringen.
Mehr als nur Feuerlöschen
Ein weitverbreitetes Missverständnis ist, dass Incident Management nur reaktives „Feuerlöschen“ sei. In Wahrheit ist es viel mehr: Es ist das Nervensystem eines stabilen IT-Betriebs. Es sorgt dafür, dass Störungen nicht im Chaos versinken, sondern strukturiert und nachvollziehbar abgearbeitet werden.
Die Hauptziele sind dabei glasklar:
- Schnelle Wiederherstellung: Der Fokus liegt darauf, den betroffenen Dienst so schnell wie möglich wieder ans Laufen zu bekommen. Zeit ist hier Geld.
- Minimierung der Auswirkungen: Negative Folgen für das Geschäft, seien es finanzielle Verluste oder Produktivitätseinbußen, müssen so gering wie nur irgend möglich gehalten werden.
- Klare Kommunikation: Alle Beteiligten, von den IT-Teams bis zu den Endanwendern, müssen transparent über den Status der Störung informiert werden.
Man kann sich einen gut etablierten Incident Management Prozess wie die Notaufnahme im Krankenhaus vorstellen. Er behandelt die akuten Symptome sofort, um den Patienten zu stabilisieren. Die tiefere Ursachenforschung überlässt er aber einem anderen Spezialisten – dem Problem Management.
Abgrenzung zum Problem Management
Diese Unterscheidung ist absolut entscheidend. Während der Incident Management Prozess die Symptome einer Störung behandelt (zum Beispiel einen Server neu startet, um eine Website wieder online zu bringen), gräbt das Problem Management nach der eigentlichen Wurzel des Übels.
Fällt derselbe Server immer wieder aus, wird aus den wiederkehrenden Incidents ein „Problem“. Das Problem Management analysiert dann, warum der Server ständig abstürzt – sei es ein Hardwaredefekt oder ein Softwarefehler – und entwickelt eine dauerhafte Lösung, um zukünftige Ausfälle von vornherein zu verhindern.
Incident und Problem Management arbeiten also Hand in Hand: Das eine löscht das akute Feuer, das andere sorgt dafür, dass es gar nicht erst wieder ausbricht. Diese Grundlage ist der Schlüssel, um Ausfallzeiten nachhaltig zu reduzieren und die Geschäftsprozesse abzusichern.
Der Lebenszyklus eines Incidents in 5 Phasen
Ein gut aufgestellter Incident Management Prozess funktioniert nicht nach Bauchgefühl, sondern folgt einem klaren, erprobten Muster – ganz ähnlich wie ein Rettungsteam, das nach einem festen Protokoll vorgeht. Jede Störung durchläuft dabei einen Lebenszyklus, der sich in fünf logische Phasen gliedert. Diese Struktur sorgt dafür, dass nichts übersehen wird, die richtigen Leute zur richtigen Zeit am richtigen Ort sind und die Lösung so schnell wie möglich gefunden wird.
Stellen wir uns das Ganze mal praktisch vor: Das zentrale CRM-System eines Unternehmens fällt aus. Der Vertrieb kann nicht mehr auf Kundendaten zugreifen, der Verkaufsprozess liegt brach. Anhand dieses Beispiels gehen wir jetzt die fünf Kernphasen des Incident Managements Schritt für Schritt durch.
Diese Infografik zeigt schön, welche grundlegenden Schritte schon vor einem tatsächlichen Incident – also in der Planungs- und Vorbereitungsphase – passieren müssen, damit im Ernstfall alles glattläuft.
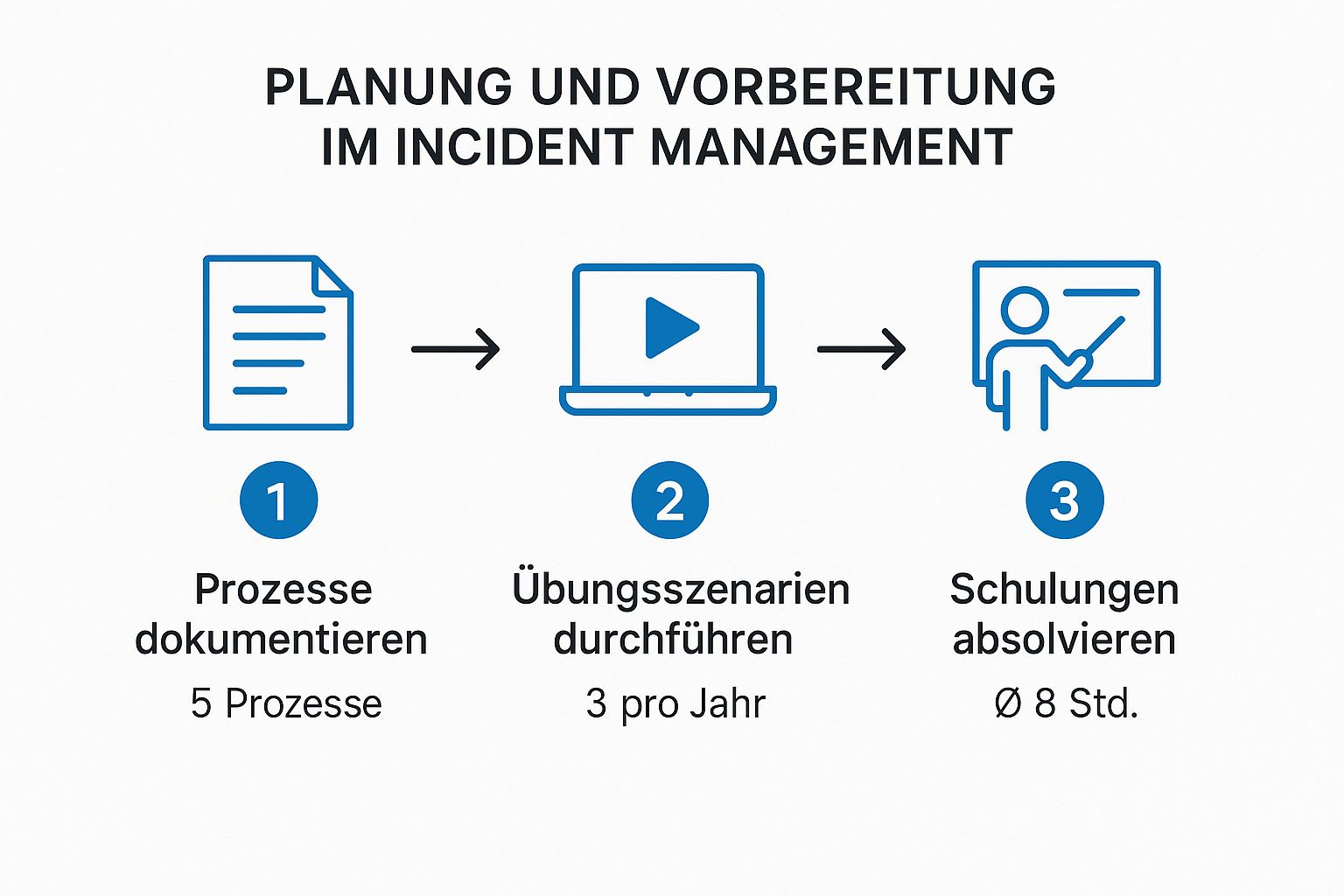
Man erkennt sofort: Ein erfolgreicher Prozess steht und fällt mit sorgfältiger Dokumentation, regelmäßigen Übungen und kontinuierlicher Schulung. Nur so kann ein Team im Ernstfall schnell und koordiniert reagieren.
Phase 1: Identifizierung und Protokollierung
Alles fängt damit an, dass eine Störung überhaupt erst bemerkt wird. Ein Incident kann auf ganz unterschiedlichen Wegen ans Licht kommen: Ein Mitarbeiter meldet per Telefon oder E-Mail, dass das CRM nicht erreichbar ist. Oder ein automatisiertes Monitoring-System schlägt Alarm, weil die Antwortzeiten des Servers einen kritischen Wert überschritten haben.
Sobald die Störung bekannt ist, folgt der erste und wichtigste Schritt: die Protokollierung. Jede einzelne Störung bekommt ein eindeutiges Ticket in einem ITSM-System (IT Service Management).
Dieses Ticket ist quasi die zentrale Akte des Incidents. Hier laufen alle Fäden zusammen und alle relevanten Informationen werden gesammelt:
- Wer meldet das Problem? Name und Kontaktdaten des Users.
- Was genau ist das Problem? Eine präzise Beschreibung der Störung („CRM-System nicht erreichbar, Fehlermeldung 503“).
- Wann trat das Problem auf? Zeitpunkt der Meldung und des ersten Auftretens.
- Welche Systeme sind betroffen? In unserem Fall das CRM-System.
Eine lückenlose Dokumentation von der ersten Minute an ist das A und O. Sie verhindert, dass wichtige Infos unter den Tisch fallen und stellt sicher, dass jeder, der an der Lösung mitarbeitet, auf dem gleichen Stand ist.
Phase 2: Kategorisierung und Priorisierung
Nicht jeder Incident ist gleich dramatisch. Ein ausgefallener Drucker im Marketing ist zwar ärgerlich, aber der Totalausfall des CRM-Systems hat ungleich gravierendere Folgen für das Kerngeschäft. Genau deshalb folgt jetzt die Kategorisierung und Priorisierung des Tickets.
Bei der Kategorisierung wird der Incident einem bestimmten Bereich zugeordnet, zum Beispiel „Software > Geschäftsanwendungen > CRM“. Das hilft ungemein dabei, die Störung ohne Umwege an das richtige Expertenteam weiterzuleiten.
Die Priorisierung ist dann der entscheidende Schritt, um die knappen Ressourcen effektiv zu lenken. Sie wird typischerweise anhand von zwei simplen Kriterien bestimmt:
- Auswirkung (Impact): Wie stark beeinträchtigt der Vorfall das Geschäft? Ein CRM-Ausfall betrifft viele Mitarbeiter und Kernprozesse, hat also eine hohe Auswirkung.
- Dringlichkeit (Urgency): Wie schnell muss eine Lösung her, um größeren Schaden abzuwenden? Da der Vertrieb stillsteht, ist die Dringlichkeit ebenfalls hoch.
Ein Incident mit hoher Auswirkung und hoher Dringlichkeit bekommt die höchste Priorität (P1) und mobilisiert sofort alle verfügbaren Kräfte.
Phase 3: Diagnose und Analyse
Jetzt beginnt die eigentliche Detektivarbeit. Das zuständige IT-Team – in unserem CRM-Beispiel vielleicht das Applikations-Support-Team – startet mit der Diagnose. Das Ziel: schnell die Ursache der Störung finden. Aber Achtung, es geht nicht darum, die tiefste Wurzel allen Übels aufzudecken (das ist Aufgabe des Problem Managements), sondern eine Ursache zu finden, die eine schnelle Wiederherstellung des Betriebs ermöglicht.
Das Team wühlt sich durch Log-Dateien, analysiert Fehlermeldungen und checkt die Server-Auslastung. Vielleicht stellt sich heraus, dass ein kürzlich eingespieltes Software-Update einen fiesen Bug enthält, der die Datenbankverbindung blockiert.
Ein wichtiger Grundsatz in dieser Phase lautet: „Wiederherstellung vor Ursachenanalyse.“ Es geht nicht darum, eine wissenschaftliche Abhandlung über den Fehler zu schreiben, sondern den Service so schnell wie möglich wieder ans Laufen zu bringen.
Während der gesamten Diagnosephase ist eine offene und kontinuierliche Kommunikation entscheidend. Betroffene User und Stakeholder sollten regelmäßig über den Fortschritt auf dem Laufenden gehalten werden. Das schafft Transparenz und beugt Frust vor.
Phase 4: Lösung und Wiederherstellung
Sobald die Ursache klar ist, wird die Lösung umgesetzt. In unserem CRM-Beispiel könnte die schnellste Lösung darin bestehen, das fehlerhafte Update einfach zurückzusetzen (Rollback). Das ist ein klassischer Workaround, der den Dienst schnell wiederherstellt, auch wenn die eigentliche Fehlerbehebung im Update selbst erst später nachgeholt wird.
Nachdem die technische Lösung implementiert ist, folgt die Wiederherstellung (Recovery). Das Team testet gründlich, ob das CRM-System wieder voll funktionsfähig ist. Erst wenn bestätigt ist, dass die Benutzer wieder normal arbeiten können, gilt der Incident aus technischer Sicht als gelöst. Das Team gibt dem meldenden User Bescheid und bestätigt, dass der Service wieder steht.
Phase 5: Abschluss und Dokumentation
Der letzte Schritt im Lebenszyklus ist der Abschluss (Closure) des Incidents. Das ist mehr als nur ein Klick auf den „Ticket schließen“-Button. Hier wird sichergestellt, dass die Lösung wirklich nachhaltig war und der Anwender zufrieden ist.
Zudem wird die gesamte Dokumentation im Ticket finalisiert. Jeder Schritt, von der ersten Meldung über die Diagnose bis zur Lösung, wird sorgfältig festgehalten. Diese Aufzeichnungen sind Gold wert. Sie fließen in eine Wissensdatenbank ein und helfen dem Team, ähnliche Störungen in Zukunft deutlich schneller zu lösen.
Interessanterweise zeigen Daten, dass der strukturierte Umgang mit Störungen in Deutschland bereits fest verankert ist. Laut mITSM-Daten bearbeiten deutsche Service-Desks täglich Hunderte von Störungen, wobei beeindruckende 85 % innerhalb der vereinbarten Service Level Agreements (SLAs) gelöst werden. Die detaillierte Dokumentation jedes Schritts im Ticket verbessert dabei kontinuierlich die Nachverfolgbarkeit für spätere Auswertungen. Mehr über die Kennzahlen im deutschen Incident Management erfahren Sie auf mitsm.de.
Um den gesamten Prozess noch einmal zu verdeutlichen, fasst die folgende Tabelle die Kernphasen übersichtlich zusammen.
Übersicht der Incident Management Phasen
Diese Tabelle fasst die Kernphasen des Prozesses zusammen und beschreibt das Ziel sowie die wichtigsten Aktivitäten jeder Phase.
| Phase | Ziel der Phase | Typische Aktivitäten |
|---|---|---|
| 1. Identifizierung & Protokollierung | Jede Störung erfassen und zentral dokumentieren. | Meldung entgegennehmen (Telefon, E-Mail, Monitoring), Ticket im ITSM-Tool anlegen, alle Basisinformationen sammeln. |
| 2. Kategorisierung & Priorisierung | Den Schweregrad bestimmen und die richtigen Ressourcen zuweisen. | Incident einer Kategorie zuordnen (z. B. Hardware, Software), Auswirkung und Dringlichkeit bewerten, Priorität festlegen (P1-P4). |
| 3. Diagnose & Analyse | Die unmittelbare Ursache für die Störung finden. | Log-Dateien prüfen, Monitoring-Daten analysieren, Hypothesen aufstellen und testen, mit betroffenen Usern sprechen. |
| 4. Lösung & Wiederherstellung | Den Service so schnell wie möglich wiederherstellen. | Workaround anwenden (z. B. Neustart, Rollback), Konfigurationsänderung vornehmen, Lösung implementieren und testen. |
| 5. Abschluss & Dokumentation | Sicherstellen, dass die Lösung erfolgreich war und Wissen für die Zukunft sichern. | Bestätigung vom User einholen, Ticket mit allen Schritten und der Lösung finalisieren, Wissensdatenbank aktualisieren. |
Diese strukturierte Vorgehensweise stellt sicher, dass selbst in hektischen Situationen ein kühler Kopf bewahrt wird und Störungen effizient und nachvollziehbar behoben werden.
Die Schlüsselrollen und ihre Verantwortlichkeiten

Ein Incident Management Prozess steht und fällt mit den Menschen, die ihn umsetzen. Man kann sich das Ganze wie eine perfekt eingespielte Rettungsmannschaft vorstellen: Jeder Handgriff sitzt, weil die Aufgabenverteilung glasklar ist. Ohne fest definierte Rollen und Verantwortlichkeiten bricht im Ernstfall schnell Chaos aus, wertvolle Zeit verrinnt ungenutzt und die Problemlösung zieht sich unnötig in die Länge.
Damit jede Störung strukturiert und effizient abgearbeitet werden kann, müssen bestimmte Schlüsselpositionen besetzt sein. Diese Rollen bilden eine Kette, die von der allerersten Meldung bis zur endgültigen Lösung reicht. So wird sichergestellt, dass das richtige Wissen zur richtigen Zeit am richtigen Ort ist.
Der First-Level-Support als erste Anlaufstelle
Der First-Level-Support, oft auch Service Desk oder Helpdesk genannt, ist die vorderste Front im Incident Management. Er ist der zentrale Ankerpunkt für alle Anwender, die eine Störung melden wollen. Seine wichtigste Aufgabe ist es, als eine Art Filter und erste Instanz für die Problembehandlung zu fungieren.
Die Mitarbeiter im First-Level-Support sind echte Kommunikationsprofis. Sie nehmen Incidents entgegen, protokollieren alle relevanten Informationen penibel im Ticketsystem und packen direkt mit an, um das Problem sofort aus der Welt zu schaffen. Gerade bei einfachen, immer wiederkehrenden Störungen gelingt das oft im Handumdrehen – einer gut gepflegten Wissensdatenbank sei Dank. Eine hohe Erstlösungsquote an dieser Stelle entlastet die nachfolgenden Support-Ebenen enorm und sorgt für zufriedene Anwender.
Ihre wichtigsten Verantwortlichkeiten sind:
- Annahme und Protokollierung: Jeder Incident wird sauber erfasst und mit allen nötigen Details dokumentiert.
- Erstdiagnose und Lösungsversuch: Standardlösungen für bekannte Probleme werden sofort angewendet.
- Kategorisierung und Priorisierung: Jeder Vorfall wird korrekt eingeordnet und nach seiner Dringlichkeit und Auswirkung bewertet.
- Kommunikation mit dem Anwender: Der betroffene Nutzer wird über den Status seines Tickets auf dem Laufenden gehalten.
Spezialisten im Second- und Third-Level-Support
Wenn der First-Level-Support eine Störung nicht auf Anhieb beheben kann, wird das Ticket eine Ebene höher gereicht. Jetzt kommen die spezialisierten Teams des Second- und Third-Level-Supports ins Spiel. Diese Experten verfügen über tiefgreifendes technisches Fachwissen in ganz bestimmten Bereichen wie Netzwerken, Datenbanken oder speziellen Softwareanwendungen.
Der Second-Level-Support kümmert sich um die komplexeren Fälle, die eine genauere Analyse erfordern. Sie tauchen tiefer in die technischen Details ein, wühlen sich durch Log-Dateien und nehmen die Systemkonfiguration unter die Lupe.
Der Third-Level-Support ist die höchste Eskalationsstufe und besteht oft aus den Entwicklern oder sogar externen Herstellern der betroffenen Systeme. Sie werden nur bei sehr komplexen, unbekannten oder kritischen Fehlern hinzugezogen, die eine Analyse des Programmcodes oder spezielles Hersteller-Know-how erfordern.
Man kann sich diese Support-Struktur wie das Gesundheitssystem vorstellen. Der Service Desk ist der Hausarzt, der die meisten Alltagsprobleme behandelt. Der Second-Level-Support ist der Facharzt, und der Third-Level-Support ist der hochspezialisierte Chirurg, der nur bei den schwierigsten Fällen gerufen wird.
Der Incident Manager als Dirigent im Krisenfall
Bei richtig schweren Störungen, den sogenannten Major Incidents, die potenziell das gesamte Unternehmen lahmlegen, tritt der Incident Manager auf den Plan. Das muss nicht zwangsläufig eine feste Position sein, sondern kann je nach Vorfall von einer entsprechend qualifizierten Person übernommen werden.
Der Incident Manager ist der Koordinator und Kommunikator in einer Person. Er löst das Problem nicht eigenhändig, sondern stellt sicher, dass alle notwendigen Ressourcen da sind, die Kommunikation zwischen den Teams reibungslos läuft und die Stakeholder auf dem Laufenden bleiben. Er behält den Überblick, trifft schnelle Entscheidungen und sorgt dafür, dass der Prozess auch unter Hochdruck eingehalten wird. Seine Autorität ist entscheidend, um den Incident schnell und kontrolliert zu einem Ende zu bringen.
Effiziente Werkzeuge für das Incident Management
Ein moderner Incident Management Prozess ohne die richtige technologische Unterstützung? Kaum noch vorstellbar. Man kann es sich wie eine hochmoderne Werkstatt vorstellen: Selbst der beste Mechaniker kann ohne die passenden Werkzeuge nur wenig ausrichten. Die richtigen Tools sind das digitale Rückgrat, das Teams dabei unterstützt, schnell, koordiniert und datengestützt auf Störungen zu reagieren.
Dabei sind diese Werkzeuge weit mehr als nur digitale Notizblöcke. Sie automatisieren Routineaufgaben, bündeln die Kommunikation an einem zentralen Ort und liefern wertvolle Analysen, um aus jeder Störung für die Zukunft zu lernen. Ihr Zusammenspiel entscheidet am Ende darüber, ob ein Incident im kontrollierten Chaos oder in effizienten Bahnen gelöst wird.
Zentrale ITSM-Plattformen als Kommandozentrale
Das Herzstück jedes technologischen Ökosystems im Incident Management ist eine ITSM-Plattform (IT Service Management). Systeme wie Jira Service Management oder ServiceNow funktionieren wie eine zentrale Kommandozentrale für alle eingehenden Störungsmeldungen. Jede Meldung wird hier als Ticket erfasst, sauber kategorisiert, priorisiert und dem richtigen Team zugewiesen.
Diese Plattformen bringen entscheidende Vorteile mit sich:
- Strukturierte Erfassung: Sie stellen sicher, dass alle notwendigen Informationen von Anfang an vollständig und einheitlich dokumentiert werden. Schluss mit dem Hin und Her wegen fehlender Details.
- Automatisierte Workflows: Routineaufgaben wie die Zuweisung von Tickets oder das Versenden von Status-Updates lassen sich einfach automatisieren. Das reduziert menschliche Fehler und spart unglaublich wertvolle Zeit.
- Volle Transparenz: Jeder Beteiligte hat jederzeit einen klaren Überblick über den Status eines Incidents. Das erleichtert die Zusammenarbeit im Team enorm.
Die richtige Plattform ist entscheidend, um die vielfältigen Herausforderungen der digitalen Transformation zu meistern und IT-Prozesse zukunftssicher aufzustellen. Lesen Sie auch, wie eine durchdachte Strategie Ihnen bei der Bewältigung der digitalen Transformation helfen kann. Für eine effektive Umsetzung des Incident Management Prozesses sind die richtigen Werkzeuge entscheidend. Erfahren Sie mehr über allgemeine spezifische Prozessmanagement Software, die über das reine Ticketing hinausgeht.
Das erweiterte Werkzeug-Ökosystem
Eine ITSM-Plattform allein macht aber noch keinen Sommer. Ein wirklich schlagkräftiger Prozess stützt sich auf ein ganzes Ökosystem von spezialisierten Werkzeugen, die nahtlos ineinandergreifen müssen.
Monitoring-Systeme: Diese Tools sind die Frühwarnsysteme Ihrer IT-Infrastruktur. Sie überwachen Netzwerke, Server und Anwendungen rund um die Uhr und schlagen Alarm, oft schon bevor ein Nutzer die Störung überhaupt bemerkt. So wird aus einer rein reaktiven eine proaktive Störungsbehebung.
Wissensdatenbanken: Eine gut gepflegte Wissensdatenbank ist das kollektive Gedächtnis des IT-Teams. Hier werden bewährte Lösungen für wiederkehrende Probleme dokumentiert. Das steigert die Erstlösungsquote drastisch und beschleunigt die Einarbeitung neuer Mitarbeiter.
Kommunikations-Tools: Bei Major Incidents zählt jede Sekunde. Tools wie Slack oder Microsoft Teams ermöglichen eine Echtzeit-Koordination in dedizierten Kanälen. So können sich alle beteiligten Experten schnell austauschen, ohne in einer Flut von E-Mails unterzugehen.
Die folgende Abbildung zeigt das Zusammenspiel der verschiedenen Prozesse im ITIL-Framework, in das sich diese Werkzeuge einbetten.
Man sieht deutlich, wie Incident Management mit anderen Prozessen wie dem Problem oder Change Management verknüpft ist – eine Integration, die durch moderne Tools erst wirklich effizient wird.
Die richtigen Werkzeuge sind nicht nur Helfer, sondern strategische Partner. Sie steigern nicht nur die Effizienz, sondern liefern auch die Daten, die für eine kontinuierliche Verbesserung des gesamten Incident Management Prozesses unerlässlich sind.
Zahlen aus der Praxis untermauern diese Bedeutung eindrucksvoll. Eine Studie unter deutschen IT-Dienstleistern zeigt, dass 65 % der Unternehmen ihre Reaktionszeit auf Meldungen dank solcher Tools in den letzten drei Jahren um durchschnittlich 35 % senken konnten. Gleichzeitig helfen intelligente Systeme dabei, die durchschnittliche Erstlösungsquote von rund 70 % weiter zu verbessern. Knapp 40 % der größeren IT-Betriebe in Deutschland setzen bereits auf maschinelles Lernen, um Incidents automatisch zu kategorisieren und zu priorisieren. Erfahren Sie mehr über die Studienergebnisse auf samhammer.de und entdecken Sie weitere Einblicke.
Incident Management vs. Problem Management verstehen

Wer den Incident Management Prozess wirklich in der Tiefe verstehen will, kommt an seinem engsten Verwandten nicht vorbei: dem Problem Management. Die Begriffe werden zwar oft in einen Topf geworfen, erfüllen aber zwei grundverschiedene, sich aber perfekt ergänzende Aufgaben. Genau dieser Unterschied ist der Schlüssel, um Störungen nicht nur zu beheben, sondern sie in Zukunft auch zu verhindern.
Stellen Sie sich einen geplatzten Wasseranschluss in Ihrem Büro vor. Das Incident Management ist die Feuerwehr: Das Team eilt herbei, dreht den Haupthahn zu und wischt das Wasser auf. Ihr einziges Ziel ist, dass der normale Betrieb so schnell wie möglich weitergehen kann. Die Arbeit muss wieder laufen.
Das Problem Management hingegen ist der erfahrene Klempnermeister. Er kommt, wenn der Boden längst trocken ist, und fragt sich: Warum ist das Rohr überhaupt geplatzt? War es altersschwach? War der Druck zu hoch? Seine Aufgabe ist es, die wahre Ursache zu finden und dafür zu sorgen, dass in einer Woche nicht schon wieder alles unter Wasser steht.
Vom Symptom zur Ursache
Diese kleine Geschichte bringt den fundamentalen Unterschied auf den Punkt. Incident Management ist pure Reaktion auf das Symptom – den Ausfall. Der Fokus liegt voll und ganz auf der schnellstmöglichen Wiederherstellung des Services. Das ist die reaktive Brandbekämpfung.
Problem Management hingegen geht proaktiv vor. Hier nimmt man sich die Zeit, um die tieferliegende Wurzel für einen oder sogar mehrere Incidents zu finden. Das Ziel ist nicht die schnelle, kurzfristige Lösung, sondern die nachhaltige Beseitigung der Fehlerquelle, damit solche Störungen gar nicht erst wieder passieren.
Ein Incident Management ohne starkes Problem Management ist, als würde man versuchen, ein leckes Boot mit einem Eimer auszuschöpfen. Man bleibt eine Weile über Wasser, aber das Loch wird man so niemals flicken. Die wahre Stärke entsteht erst, wenn beide Prozesse ineinandergreifen.
Besonders gut sieht man diese Zusammenarbeit, wenn bestimmte Störungen immer wiederkehren. Fällt zum Beispiel jeden Montagmorgen derselbe Server aus, wird aus diesen wiederholten Incidents ein „Problem“ erstellt. Ab diesem Moment übernimmt das Problem Management und startet eine systematische Untersuchung.
Die Synergie für eine stabile IT nutzen
Man könnte sagen, die Daten aus dem Incident Management sind der Treibstoff für ein wirksames Problem Management. Durch die sorgfältige Analyse von Incident-Tickets lassen sich Muster erkennen, die auf versteckte Schwachstellen in der IT-Landschaft hindeuten.
Dieser datengestützte Ansatz ist Gold wert. Analysen deutscher Serviceprovider zeigen, dass rund 30 % aller Incidents durch noch ungelöste, tieferliegende Probleme verursacht werden. Mit einem gut aufgesetzten Problem Management sind jährliche Reduktionen der Incident-Anzahl um 10 bis 15 % absolut realistisch.
Die nahtlose Verknüpfung beider Prozesse ist ein klares Kennzeichen für reife IT-Organisationen und ein entscheidender Baustein für zuverlässige Managed IT-Services. Nur wenn Symptombekämpfung und Ursachenforschung Hand in Hand gehen, kann eine wirklich stabile und widerstandsfähige IT-Umgebung entstehen.
Bewährte Praktiken für einen exzellenten Prozess
Ein funktionierender Incident Management Prozess ist das Fundament. Aber wahre Exzellenz? Die entsteht erst, wenn man ihn kontinuierlich auf den Prüfstand stellt und an den richtigen Stellschrauben dreht. Es sind oft die kleinen Details, die einen guten von einem herausragenden Prozess unterscheiden – und genau diese Details sorgen für schnellere Lösungen, zufriedenere Anwender und eine IT, die einfach läuft.
Die folgenden Punkte sind keine trockene Theorie, sondern praxiserprobte Hebel, die Sie direkt umsetzen können. Betrachten Sie sie als Checkliste, um Ihren eigenen Prozess auf das nächste Level zu heben.
Klare Priorisierung und realistische SLAs
Nicht jede Störung ist gleich. Ein Druckerproblem ist ärgerlich, ein Ausfall des ERP-Systems legt den ganzen Betrieb lahm. Deshalb führt kein Weg an einer glasklaren Priorisierungsmatrix vorbei. Diese Matrix muss unmissverständlich definieren, wie Incidents eingestuft werden – typischerweise basierend auf ihrer Auswirkung (Impact) und ihrer Dringlichkeit (Urgency). So entstehen Kategorien wie P1 für kritische Notfälle bis P4 für kleinere Ärgernisse.
Parallel dazu brauchen Sie realistische Service Level Agreements (SLAs). Ein SLA ist mehr als nur eine Zahl; es ist ein handfestes Versprechen an Ihre Anwender, das festlegt, wie schnell reagiert und gelöst wird.
Worauf es bei guten SLAs ankommt:
- Messbar: Definieren Sie konkrete Zeitfenster für jede Prioritätsstufe. Zum Beispiel: Eine Reaktion auf einen P1-Vorfall muss innerhalb von 15 Minuten erfolgen.
- Realistisch: Setzen Sie Ziele, die Ihr Team auch wirklich erreichen kann. Nichts ist demotivierender als unerreichbare Vorgaben, die nur Frust auf allen Seiten erzeugen.
- Transparent: Kommunizieren Sie die SLAs offen und ehrlich. So weiß jeder im Unternehmen, was er im Störungsfall erwarten kann.
Ein gut durchdachtes SLA-System schafft nicht nur Verbindlichkeit. Es liefert auch die objektive Grundlage, um die Leistung des Teams zu messen und den Prozess immer weiter zu verbessern.
Aufbau einer umfassenden Wissensdatenbank
Stellen Sie sich eine gut gepflegte Wissensdatenbank als das kollektive Gedächtnis Ihres IT-Teams vor. Sie ist ein unschätzbar wertvolles Werkzeug, um die Erstlösungsquote dramatisch zu erhöhen. Jede gelöste Störung ist eine gewonnene Erkenntnis, die für die Zukunft festgehalten werden sollte.
Dokumentieren Sie Lösungen für wiederkehrende Probleme – am besten in Form von einfachen Anleitungen, Checklisten oder kurzen How-to-Artikeln. Das befähigt den First-Level-Support, viel mehr Anfragen direkt im ersten Anlauf zu klären, ohne sie an Spezialisten weiterreichen zu müssen. Das Ergebnis: Weniger Eskalationen, schnellere Hilfe für den Anwender und eine spürbare Entlastung für die nachgelagerten Teams.
Dedizierter Prozess für Major Incidents
Ein Serverausfall, der die gesamte Produktion stoppt, ist kein gewöhnlicher Incident. Solche Major Incidents – also Großstörungen – verlangen nach einem eigenen, beschleunigten Krisenprotokoll mit klaren Eskalationspfaden und festen Kommunikationsketten.
Für diese Fälle muss ein Incident Manager benannt werden, der im Ernstfall den Hut aufhat, die Maßnahmen koordiniert und als zentrale Anlaufstelle für alle Stakeholder dient. Dieser spezielle Prozess sorgt dafür, dass bei kritischen Störungen keine wertvolle Zeit durch Zuständigkeitsgerangel verloren geht und alle Beteiligten koordiniert an einem Strang ziehen. Eine solche Notfallplanung ist übrigens ein zentraler Baustein jeder professionellen IT-Strategie-Beratung, die darauf abzielt, Geschäftsrisiken proaktiv zu minimieren.
Kontinuierliche Messung und Verbesserung
Ein alter Management-Grundsatz besagt: Was man nicht misst, kann man nicht verbessern. Definieren Sie deshalb klare Key Performance Indicators (KPIs), um die Wirksamkeit Ihres Incident Management Prozesses schwarz auf weiß zu sehen.
Typische und bewährte KPIs sind hier:
- Mean Time to Resolution (MTTR): Die durchschnittliche Zeit, die von der Meldung einer Störung bis zu ihrer endgültigen Lösung vergeht.
- First Contact Resolution Rate: Der prozentuale Anteil der Incidents, die direkt beim ersten Kontakt mit dem Support gelöst werden können.
- SLA Compliance Rate: Wie viel Prozent der Incidents wurden innerhalb der versprochenen SLA-Zeiten behoben?
Analysieren Sie diese Kennzahlen regelmäßig. Sie sind Ihr Kompass, der Ihnen genau zeigt, wo es hakt und wo es Engpässe gibt. Nutzen Sie diese Daten, um gezielte Verbesserungen anzustoßen und Ihren Prozess Schritt für Schritt zu perfektionieren.
Häufig gestellte Fragen
Zum Abschluss wollen wir noch ein paar Fragen klären, die im Alltag immer wieder auftauchen. Betrachten Sie diesen Abschnitt als kleinen Spickzettel, der Ihnen schnelle und praxisnahe Antworten auf die wichtigsten Punkte rund um das Incident Management liefert.
Was ist der Hauptunterschied zwischen einem Incident und einem Service Request?
Diese Frage ist im IT-Alltag absolut entscheidend, denn die Unterscheidung bestimmt den gesamten weiteren Prozess.
Stellen Sie sich vor, Ihr E-Mail-Programm stürzt ständig ab oder das WLAN ist ausgefallen. Das ist ein Incident: eine ungeplante Störung, die Sie an der Arbeit hindert. Hier geht es einzig und allein darum, den Normalzustand so schnell wie möglich wiederherzustellen.
Ein Service Request ist hingegen etwas völlig anderes. Hierbei handelt es sich um eine geplante Anfrage, zum Beispiel wenn Sie einen neuen Laptop für einen Mitarbeiter bestellen, Zugriff auf ein Netzlaufwerk benötigen oder eine spezielle Software installiert haben möchten. Es ist kein Fehler, sondern ein Standardvorgang.
Warum ist eine hohe Erstlösungsquote so wichtig?
Die Erstlösungsquote (im Englischen First Contact Resolution Rate) ist eine der wichtigsten Kennzahlen im Support. Sie zeigt, wie viele Anfragen direkt beim ersten Kontakt gelöst werden, ohne dass ein Ticket an die nächste Eskalationsstufe weitergereicht werden muss.
Eine hohe Quote ist Gold wert, und das aus gutem Grund:
- Zufriedene Anwender: Wer bekommt nicht gerne sofort geholfen? Schnelle Lösungen bedeuten weniger Frust und produktivere Mitarbeiter.
- Geringere Kosten: Jede Weiterleitung eines Tickets an einen Spezialisten kostet Zeit und damit Geld. Wenn der First-Level-Support die meisten Probleme direkt löst, spart das Unternehmen bares Geld.
- Freie Ressourcen für komplexe Fälle: Ihre hochqualifizierten Experten im Second- oder Third-Level-Support werden entlastet und können sich auf die wirklich kniffligen Probleme konzentrieren, anstatt sich mit Standardanfragen zu beschäftigen.
Eine hohe Erstlösungsquote ist mehr als nur eine schöne Statistik. Sie ist ein klares Indiz für einen exzellenten First-Level-Support und eine gut gepflegte Wissensdatenbank. Sie beweist, dass Ihr Team perfekt aufgestellt ist, um die täglichen Herausforderungen im Handumdrehen zu meistern.
Was versteht man unter einem Major Incident?
Ein Major Incident ist sozusagen der "Code Red" im IT-Support. Es handelt sich um eine massive Störung mit katastrophalen Auswirkungen auf das gesamte Unternehmen. Denken Sie an den Totalausfall des Online-Shops am Black Friday oder einen kompletten Produktionsstillstand durch einen Serverausfall – das ist ein Major Incident.
Solche Vorfälle erfordern einen eigenen, beschleunigten Notfallprozess. Ein dedizierter Incident Manager übernimmt sofort die Leitung, es werden klare Kommunikationskanäle zu allen wichtigen Stakeholdern (Geschäftsführung, Abteilungsleiter) eingerichtet, und alle verfügbaren Kräfte werden gebündelt, um das Problem mit allerhöchster Priorität zu lösen.
Wie hängt Incident Management mit ITIL zusammen?
ITIL (Information Technology Infrastructure Library) ist quasi das Standardwerk für professionelles IT-Service-Management (ITSM). Es ist ein weltweit anerkannter Rahmen, der Best Practices für die Bereitstellung und Verwaltung von IT-Dienstleistungen beschreibt.
Innerhalb dieses riesigen Frameworks ist der Incident Management Prozess eine der bekanntesten und wichtigsten Disziplinen. ITIL gibt nicht nur vor, was im Incident Management zu tun ist – also die Phasen, Rollen und Verantwortlichkeiten –, sondern beschreibt auch, wie dieser Prozess nahtlos mit anderen wichtigen Prozessen wie dem Problem Management, Change Management oder Service Request Management verzahnt wird.
Wer sein Incident Management nach ITIL-Standards aufbaut, sorgt dafür, dass die IT-Services strukturiert, professionell und nach einem bewährten globalen Standard funktionieren.
Sind Sie bereit, Ihre IT-Infrastruktur auf das nächste Level zu heben und Ihre Prozesse nach höchsten Standards abzusichern? Deeken.Technology GmbH ist Ihr ISO 27001-zertifizierter Partner für umfassende IT-Services und NIS-2-Compliance. Kontaktieren Sie uns und lassen Sie uns gemeinsam eine robuste und zukunftssichere IT-Strategie für Ihr Unternehmen entwickeln: https://deeken-group.com

Comments