Wenn Anwender morgens melden, dass das ERP zäh reagiert, RDP-Sitzungen stocken oder ein Server zwar erreichbar ist, aber jede Aktion quälend langsam dauert, beginnt die Fehlersuche fast immer an derselben Stelle. cpu auslastung anzeigen ist dann kein Selbstzweck, sondern der schnellste Einstieg in eine belastbare Diagnose.
In der Praxis ist die CPU-Anzeige oft der erste Indikator, aber selten die ganze Geschichte. Hohe Last kann auf legitime Rechenarbeit hindeuten, auf einen schlecht optimierten Dienst, auf einen blockierenden Einzelprozess oder auf ein Sicherheitsproblem. Wer nur kurz in einen Task-Manager schaut, sieht Symptome. Wer die Werte richtig interpretiert und sauber protokolliert, schafft eine Grundlage für Performance, Kapazitätsplanung und Auditfähigkeit.
Warum die CPU-Auslastung eine kritische Kennzahl ist
Der typische Ablauf ist bekannt. Ein Fachbereich meldet eine langsame Anwendung. Die Infrastruktur wirkt auf den ersten Blick stabil, Speicher ist ausreichend vorhanden, die Netzwerkverbindung steht. Erst beim Blick auf die CPU wird klar, dass ein Server unter Last steht und Anfragen nicht mehr sauber abarbeitet.
CPU-Auslastung zeigt, wie viel Prozent der verfügbaren Rechenzeit tatsächlich genutzt werden. Der Maximalwert liegt bei 100 Prozent, und ein dauerhaft hoher Wert ist in der täglichen Administration ein Warnsignal. Ein konstanter Auslastungsstatus von 80 bis 90 Prozent deutet nach Best-Practice-Standards darauf hin, dass ein CPU-Upgrade oder zusätzliche Prozessoren notwendig sein könnten, um Engpässe zu vermeiden, wie der Leitfaden von IONOS zur CPU-Auslastung beschreibt.
Das Entscheidende ist aber: Ein hoher Wert ist kein Fehlerbild, sondern ein Hinweis. Die eigentliche Frage lautet, welcher Prozess die Last erzeugt, wie lange der Zustand anhält und ob die Last geschäftskritische Dienste beeinträchtigt.
Praxisregel: Eine kurzzeitige Spitze ist oft unkritisch. Dauerlast verändert Prioritäten. Dann geht es nicht mehr nur um Fehlersuche, sondern um Stabilität im Betrieb.
In Unternehmen mit mehreren Fachanwendungen wird CPU-Monitoring schnell zur betriebswirtschaftlichen Kennzahl. Wenn Datenbankserver, Terminalserver oder Schnittstellenserver regelmässig an Leistungsgrenzen laufen, betrifft das nicht nur die IT. Dann steigen Bearbeitungszeiten, Supporttickets und das Risiko, dass Geschäftsprozesse aus dem Takt geraten.
Deshalb reicht es nicht, CPU-Last nur dann anzusehen, wenn es bereits brennt. Wer sauber monitoriert, erkennt Muster früher und kann entscheiden, ob Tuning genügt, ob ein Workload verlagert werden sollte oder ob die Infrastruktur strukturell zu klein dimensioniert ist.
Grafische Tools für den schnellen Überblick auf Desktops
Montagmorgen, mehrere Anwender melden zähe Reaktionszeiten, Outlook hängt, der Browser stockt. Auf dem Desktop zählt dann der schnelle Sichtcheck. Grafische CPU-Tools helfen, in wenigen Sekunden zwischen Einzelfall, breiter Lastspitze und möglichem Sicherheitsereignis zu unterscheiden.

Windows mit Task-Manager
Unter Windows bleibt der Task-Manager das praktischste Werkzeug für die Erstbewertung. Im Reiter Leistung sehen Sie sofort, ob die CPU nur kurz ausschlägt oder ob die Last über einen längeren Zeitraum hoch bleibt. Für den Service Desk ist das oft der schnellste Weg zur richtigen Eskalation.
Für die Praxis sind vier Punkte relevant:
Verlauf statt Momentaufnahme prüfen
Eine hohe Zahl allein reicht nicht. Entscheidend ist, ob die Kurve wieder abfällt oder oben kleben bleibt.Im Reiter Prozesse nach CPU sortieren
So erkennen Sie zügig, ob ein Browser-Tab, ein Update-Dienst, ein Scanner oder eine Fachanwendung die Last erzeugt.Logische Prozessoren mitdenken
Wenn Benutzer über Hänger klagen, die Gesamtlast aber moderat aussieht, steckt oft ein einzelner Thread dahinter. Das sieht man im Gesamtwert nur eingeschränkt.Betriebskontext bewerten
Geplante Scans, Patching, Synchronisation oder Videokonferenzen erzeugen legitime Last. Ungeplante Peaks durch unbekannte Prozesse verdienen dagegen eine genauere Prüfung, auch aus Security-Sicht.
Gerade in ISO-27001-nahen Betriebsprozessen ist dieser erste Blick mehr als Komfort. Wenn ein unbekannter Prozess dauerhaft CPU zieht, ist das nicht nur ein Performance-Thema. Dann geht es auch um Nachvollziehbarkeit, saubere Incident-Bewertung und die Frage, ob ein Endpunkt auffällig geworden ist.
Wer Linux-Desktops mitbetreut, findet in der Übersicht zu Task-Manager-Alternativen unter Ubuntu eine hilfreiche Brücke zwischen grafischer Ansicht und tieferer Prozessanalyse.
Ein kurzer CPU-Blick reicht für spontane Störungen. Bei wiederkehrenden Auffälligkeiten brauchen Sie Prozessbezug, Zeitverlauf und im Unternehmen meist auch eine dokumentierte Bewertung.
macOS mit Aktivitätsanzeige
Auf dem Mac übernimmt die Aktivitätsanzeige diese Aufgabe. In gemischten Umgebungen mit Design, Entwicklung und Office-Arbeitsplätzen ist sie nützlich, weil sie CPU-Verbrauch sauber nach Prozessen und Lastarten aufschlüsselt.
Darauf achte ich im Betrieb zuerst:
- Hohe Benutzerlast spricht oft für rechenintensive Anwendungen wie Browser, lokale Builds, Rendering oder Analyse-Tools.
- Hohe Systemlast weist eher auf Hintergrunddienste, Kernel-nahe Vorgänge oder Treiberprobleme hin.
- Viel Inaktivität bedeutet freie Reserve. Dann liegt die gefühlte Langsamkeit häufig nicht an der CPU, sondern an Speicher, I/O oder Netzabhängigkeiten.
Was grafische Tools leisten und was nicht
Grafische Werkzeuge sind stark, wenn Support schnell entscheiden muss. Sie helfen bei der Erstdiagnose, bei der Plausibilitätsprüfung von Nutzerbeschwerden und bei der Einordnung, ob sofort gehandelt werden muss.
Für Unternehmen haben sie aber klare Grenzen. Sie liefern meist keinen belastbaren Langzeitverlauf, taugen nur eingeschränkt für automatische Warnungen und reichen für Audit-Nachweise allein nicht aus. Wer NIS-2- oder ISO-27001-Anforderungen sauber bedienen will, braucht CPU-Daten nicht nur sichtbar, sondern auch historisiert, korrelierbar und nachvollziehbar dokumentiert.
Genau deshalb bleiben Desktop-Tools ein guter Startpunkt. Für Kapazitätsplanung, Compliance und belastbare Sicherheitsbewertung reichen sie allein nicht.
Kommandozeilen-Befehle für Server und Power-User
Auf einem produktiven Server zählt nicht, was auf dem Bildschirm gut aussieht, sondern was sich sauber prüfen, wiederholen und dokumentieren lässt. Genau dort spielt die Kommandozeile ihre Stärke aus. CPU-Werte lassen sich per Shell und PowerShell schnell erfassen, in Skripte übernehmen und in Monitoring- oder Audit-Prozesse einbinden. Das ist für den Betrieb nützlich und für ISO 27001 oder NIS-2 oft der Unterschied zwischen einer Momentaufnahme und einem belastbaren Nachweis.
Linux-Werkzeuge für den Alltag
Unter Linux reichen meist wenige Befehle.
top ist der schnellste Einstieg, wenn ein Server auffällig wird. Sie sehen sofort, welche Prozesse CPU-Zeit verbrauchen, wie sich die Last verteilt und ob das System gerade wirklich unter Druck steht. Für die Erstdiagnose im laufenden Betrieb ist das oft der sinnvollste erste Schritt.
htop arbeitet komfortabler, wenn es installiert ist. Die Ansicht ist lesbarer, Sortierung und Filter gehen schneller, und auf Incident-Calls spart das Minuten. Der Nachteil ist einfach: Das Tool ist nicht überall vorhanden, während top auf fast jedem Linux-System verfügbar ist.
iostat und sar sind wichtig, sobald die Frage nicht mehr nur lautet: "Ist die CPU hoch?" Dann geht es um Ursachen. Bei Datenbankservern, VMs oder Hosts mit vielen Hintergrundjobs entsteht hohe CPU-Last oft zusammen mit Storage-Wartezeiten, Steal Time oder Lastspitzen zu festen Zeiten. iostat hilft bei der Abgrenzung zwischen CPU- und I/O-Problem. sar liefert historische Werte und zeigt, ob eine Spitze ein Einzelfall war oder Teil eines wiederkehrenden Musters. Genau solche Verläufe brauchen Unternehmen für Kapazitätsplanung, saubere Störungsanalysen und nachvollziehbare Betriebsdokumentation.
Für Administratoren, die Linux-Server regelmässig per Shell betreuen, lohnt ein strukturierter Überblick über gängige Linux-Terminal-Befehle für den Admin-Alltag.
Windows auf der Kommandozeile
Auf Windows-Servern ist PowerShell das passende Werkzeug für wiederholbare Prüfungen. Mit Get-Counter lässt sich die CPU-Last skriptbar abfragen, speichern und an bestehende Betriebsroutinen übergeben. Das passt deutlich besser zu standardisierten Admin-Prozessen als manuelles Klicken durch einzelne Oberflächen.
Typische Einsatzfälle sind:
- Ad-hoc-Analyse bei Lastspitzen oder auffälligen Diensten
- Geplante Erfassung über Skripte und Aufgabenplanung
- Übergabe an Monitoring- und Reporting-Prozesse
- Vergleich mehrerer Server ohne interaktive GUI-Anmeldung
Gerade in regulierten Umgebungen ist das ein praktischer Vorteil. Messwerte aus Skripten lassen sich versionieren, standardisieren und im Change- oder Incident-Prozess sauber referenzieren.
Vergleich von Kommandozeilen-Tools zur CPU-Überwachung
| Befehl | Betriebssystem | Hauptmerkmal | Ideal für… |
|---|---|---|---|
top |
Linux | Echtzeitübersicht über Prozesse und Last | schnelle Erstdiagnose auf Servern |
htop |
Linux | interaktive, lesbare Prozessansicht | manuelle Analyse unter Zeitdruck |
iostat |
Linux | CPU und I/O gemeinsam betrachten | Abgrenzung zwischen CPU- und Storage-Engpass |
sar |
Linux | historische CPU-Erfassung und Verlauf | Trendanalyse, Rückblick, Dokumentation |
Get-Counter |
Windows | skriptbare Abfrage per PowerShell | Automatisierung und wiederholbare Prüfungen |
Auf Servern ist meist das Tool am nützlichsten, das sich in Betrieb, Dokumentation und Eskalation sauber einfügt.
Was in der Praxis funktioniert und was nicht
Im Alltag funktioniert die Kombination aus Echtzeitansicht und Verlauf am besten. top oder Get-Counter zeigen die akute Lage. sar oder ein zentrales Monitoring zeigen, ob die Last seit Stunden steigt, jeden Montag nach einem Batchlauf auftaucht oder nur während des Backups sichtbar wird.
Ohne Historie bleibt die Analyse oft unvollständig. Dann wird auf den Prozess geschaut, der gerade oben steht, obwohl die eigentliche Ursache ein geplanter Job, ein Storage-Engpass oder ein überbuchter Hypervisor ist.
In virtualisierten Umgebungen kommt ein weiterer Punkt dazu. Hohe CPU-Werte auf dem Gast sagen noch nicht, ob der Gast selbst das Problem verursacht. Auch vCPU-Zuteilung, Scheduling und Nachbarsysteme auf dem Host können die Messung beeinflussen. Wer CPU-Auslastung per Kommandozeile prüft, bekommt starke Signale. Für belastbare Entscheidungen in Betrieb, Sicherheit und Compliance braucht diese Sicht aber immer den Systemkontext.
CPU-Werte richtig deuten: Load Average vs. Prozent-Auslastung
Wer cpu auslastung anzeigen will, bekommt meist sehr schnell Zahlen. Schwieriger ist die Interpretation. Besonders häufig werden Prozent-Auslastung und Load Average durcheinandergebracht, obwohl beide etwas anderes aussagen.
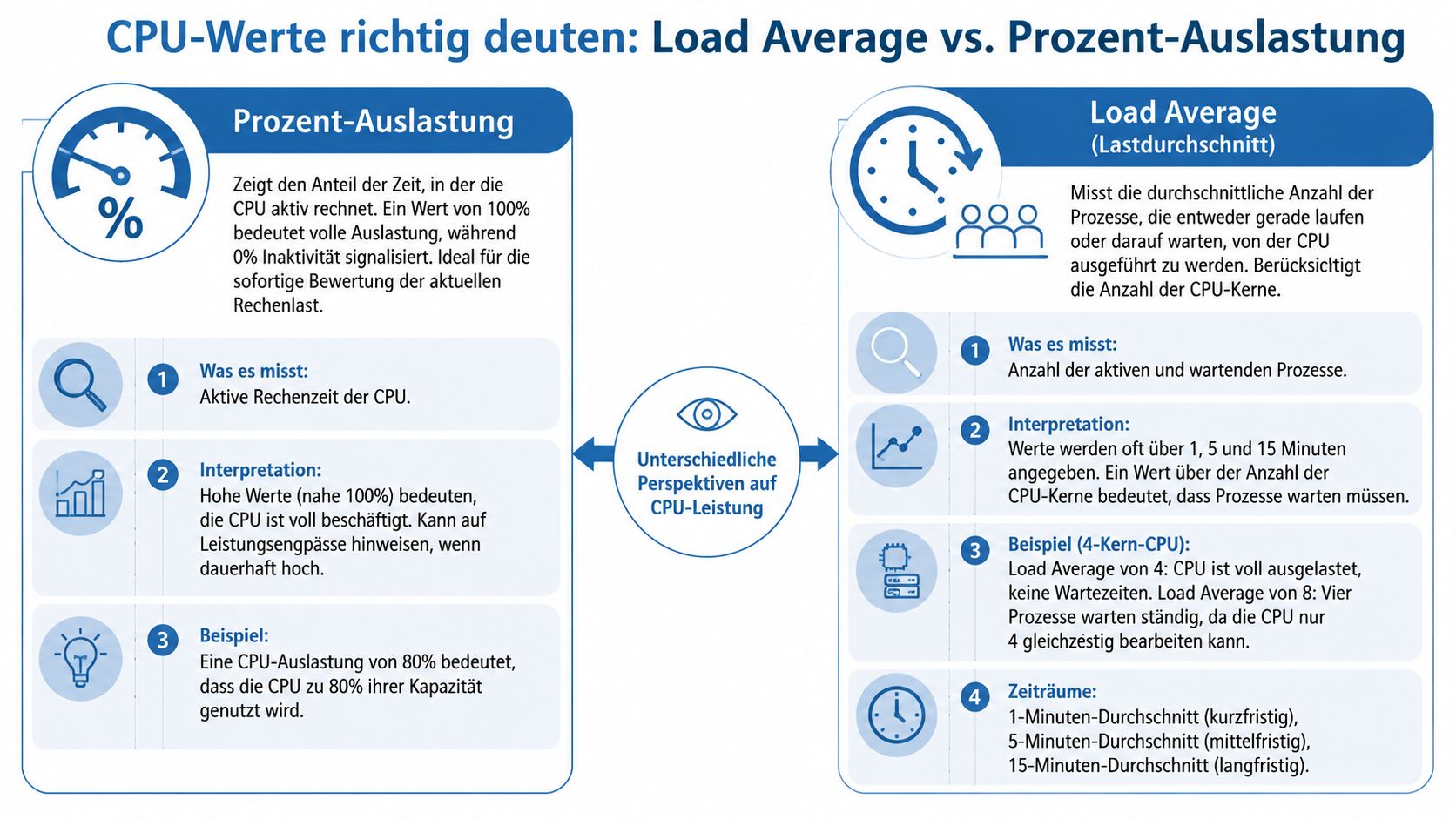
Prozent-Auslastung beschreibt aktuelle Rechenarbeit
Die prozentuale CPU-Auslastung zeigt, wie stark die CPU gerade beschäftigt ist. Für die akute Bewertung ist dieser Wert ideal. Sie sehen sofort, ob ein System aktuell unter Last steht oder noch Reserven hat.
Im Tagesgeschäft ist das der Wert, den Support und Helpdesk zuerst nutzen. Er eignet sich besonders gut für spontane Prüfungen, etwa wenn ein Dienst gerade hängt oder ein Client-Rechner unerwartet laut wird.
Load Average zeigt die Warteschlange
Der Load Average ist eine andere Perspektive. Vereinfacht gesagt zeigt er, wie viele Prozesse gerade arbeiten oder auf Rechenzeit warten. Deshalb ist er für Linux-Server oft aussagekräftiger als ein einzelner Prozentwert.
Eine einfache Analogie hilft. Die CPU-Auslastung ist wie die Frage, ob die Kasse im Supermarkt gerade arbeitet. Der Load Average zeigt, wie lang die Schlange vor der Kasse ist. Eine Kasse kann dauerhaft beschäftigt sein, ohne dass die Schlange kritisch ist. Problematisch wird es, wenn immer mehr Leute warten müssen.
Warum die Pro-Kern-Sicht entscheidend ist
Ein Gesamtwert kann täuschen. Bei einem System mit 4 Prozessoren führt die Konstellation, dass ein Prozessor mit 100 Prozent arbeitet und die anderen 3 untätig sind, nur zu einer Gesamtsystemlast von 25 Prozent. Genau dieses Beispiel zeigt, warum eine Pro-Kern-Analyse unverzichtbar ist, wie im bereits erwähnten IONOS-Leitfaden erläutert.
Das ist in der Praxis besonders relevant bei:
- älteren Fachanwendungen, die nicht sauber parallelisieren
- Datenbankabfragen, die einzelne Threads stark belasten
- virtuellen Maschinen, bei denen ein Dienst an einem Kern hängt
- Sicherheitsvorfällen, bei denen ein einzelner Prozess auffällig Last erzeugt
Niedrige Gesamtlast heisst nicht automatisch, dass alles gesund läuft. Ein einziger blockierter Kern kann für den betroffenen Dienst bereits reichen.
Eine praxistaugliche Lesart
Wenn die Prozent-Auslastung hoch ist, prüfen Sie, welcher Prozess die Last erzeugt. Wenn der Load Average hoch ist, prüfen Sie, ob Prozesse warten müssen. Wenn die Gesamtanzeige unauffällig ist, aber Benutzer über schlechte Performance klagen, prüfen Sie die Verteilung pro Kern.
Diese drei Fragen zusammen liefern oft mehr als jede isolierte Kennzahl.
Proaktives Monitoring für Unternehmen einrichten
Reaktives Handeln kostet Zeit, Nerven und oft auch Vertrauen im Fachbereich. Wer CPU-Werte nur dann prüft, wenn bereits Tickets eingehen, arbeitet zu spät. Unternehmen brauchen einen Betrieb, der Auffälligkeiten erkennt, bevor Anwender sie melden.

Alerts sind nötig, aber nicht genug
Monitoring-Systeme wie PRTG oder Zabbix können CPU-Gesamtlast und Last einzelner Kerne überwachen und Schwellwerte für Warnungen definieren. Das ist wichtig, aber es reicht nicht. Ein Alert sagt nur, dass jetzt gerade etwas auffällig ist. Er beantwortet nicht, ob sich ein Problem seit Wochen aufbaut.
Genau dort liegt in vielen mittelständischen Umgebungen die Lücke. Kaum adressiert wird die strategische Frage, wie deutsche Mittelständler CPU-Auslastungstrends zur ROI-orientierten Kapazitätsplanung nutzen, um Entscheidungen über Hardware-Upgrades oder Cloud-Migrationen datenbasiert zu treffen, wie die Produktseite zu CPU-Monitoring bei Checkmk als unterversorgte Perspektive beschreibt.
So sieht ein brauchbares Setup aus
Ein sinnvolles Monitoring ist nicht kompliziert, aber konsequent aufgebaut:
Kurzfristige Warnungen
Meldungen bei anhaltender hoher Last auf geschäftskritischen Systemen. Nicht jede Spitze muss alarmieren. Relevant sind Zustände, die den Betrieb beeinträchtigen.Historische Aufzeichnung
Trends über Wochen und Monate zeigen, ob ein Server nur gelegentlich arbeitet oder systematisch an Grenzen kommt.Kontextdaten
CPU allein genügt nicht. Zuordnung zu Diensten, Wartungsfenstern, Backups und Patchläufen verhindert Fehlinterpretationen.Management-taugliche Sicht
IT-Leitung und Geschäftsführung brauchen keine Rohdaten, sondern klare Aussagen zu Stabilität, Risiken und Handlungsbedarf. Für die Verdichtung solcher Betriebsdaten in verständliche Übersichten können Stay Digital Business Dashboards als Beispiel für sauberes Reporting nützlich sein.
Vom Messen zum Entscheiden
In gut organisierten IT-Umgebungen dient CPU-Monitoring nicht nur dem Incident Management. Es unterstützt Investitionsentscheidungen. Wenn ein Workload zu bestimmten Zeiten regelmässig an Grenzen stösst, kann die richtige Antwort ein Tuning sein. Es kann aber ebenso sinnvoll sein, Dienste in eine skalierbare Umgebung zu verlagern oder ein System gezielt zu erweitern.
Für die operative Umsetzung lohnt ein Blick auf den Aufbau von Server-Monitoring im Unternehmensumfeld. Solche Konzepte sind deutlich belastbarer als eine Sammlung lose gesetzter Alarmwerte.
Als Werkzeugoption kann auch ein spezialisiertes Systemhaus-Tool sinnvoll sein. Deeken.Technology GmbH bietet beispielsweise ein Tool an, das Temperaturen und CPU-Auslastung zuverlässig auslesen kann und zusätzlich weitere Systeminformationen bereitstellt. Entscheidend ist dabei nicht die Marke, sondern dass sich die Daten sauber in Betrieb und Dokumentation einfügen.
Monitoring im Kontext von Compliance und Sicherheit
Spätestens bei ISO 27001, internen Audits oder NIS-2-Anforderungen reicht es nicht mehr, CPU-Werte nur gelegentlich anzusehen. Dann geht es um Nachweisbarkeit, um geordnete Prozesse und um die Frage, ob Auffälligkeiten erfasst, bewertet und bei Bedarf eskaliert werden.
Für KMU mit NIS-2-Anforderungen ist oft unklar, wie CPU-Auslastungsdaten dokumentiert und in Compliance-Audits nachgewiesen werden müssen, weil viele Quellen nicht erklären, wie Monitoring-Daten für Nachweispflichten strukturiert werden sollten. Genau auf diese Lücke weist die Einordnung zu Cloud-Monitoring und Compliance bei STACKIT hin.
Warum CPU-Monitoring auch ein Sicherheitsthema ist
Ungewöhnliche CPU-Last ist nicht nur ein Performance-Signal. Sie kann ein Frühindikator für einen Sicherheitsvorfall sein. Wenn ein Server ausserhalb üblicher Betriebszeiten dauerhaft rechnet, ein einzelner Prozess plötzlich Last erzeugt oder ein Endpoint ohne erkennbaren Grund auffällig wird, gehört das in den Incident-Response-Prozess.
Wichtig ist dabei die Verbindung aus Technik und Organisation:
- Messung liefert das Signal
- Protokollierung schafft Nachvollziehbarkeit
- Bewertung trennt normales Verhalten von Auffälligkeiten
- Eskalation macht aus Monitoring einen wirksamen Sicherheitsprozess
Wer CPU-Werte nur als Performance-Zahl behandelt, verschenkt einen frühen Sensor für Betriebs- und Sicherheitsrisiken.
In ISO-27001-nahen Betriebsmodellen ist deshalb nicht nur das Monitoring selbst relevant, sondern auch die Frage, wie Daten aufbewahrt, ausgewertet und in Audits vorgelegt werden können. Genau dort trennt sich spontane Administration von professionellem IT-Betrieb.
Wenn Sie CPU-Auslastung nicht nur anzeigen, sondern sauber überwachen, dokumentieren und für NIS-2- oder ISO-27001-nahe Prozesse nutzbar machen wollen, unterstützt Sie Deeken.Technology GmbH bei Konzeption, Monitoring-Architektur und der Einbindung in einen belastbaren IT-Betrieb.

